 A crowd-sourced, entirely cloud-based challenge, with the aim of developing and assessing new algorithms capable of identifying and correcting mislabeled samples using multi-omics data.
A crowd-sourced, entirely cloud-based challenge, with the aim of developing and assessing new algorithms capable of identifying and correcting mislabeled samples using multi-omics data.
Mislabeling Challenge
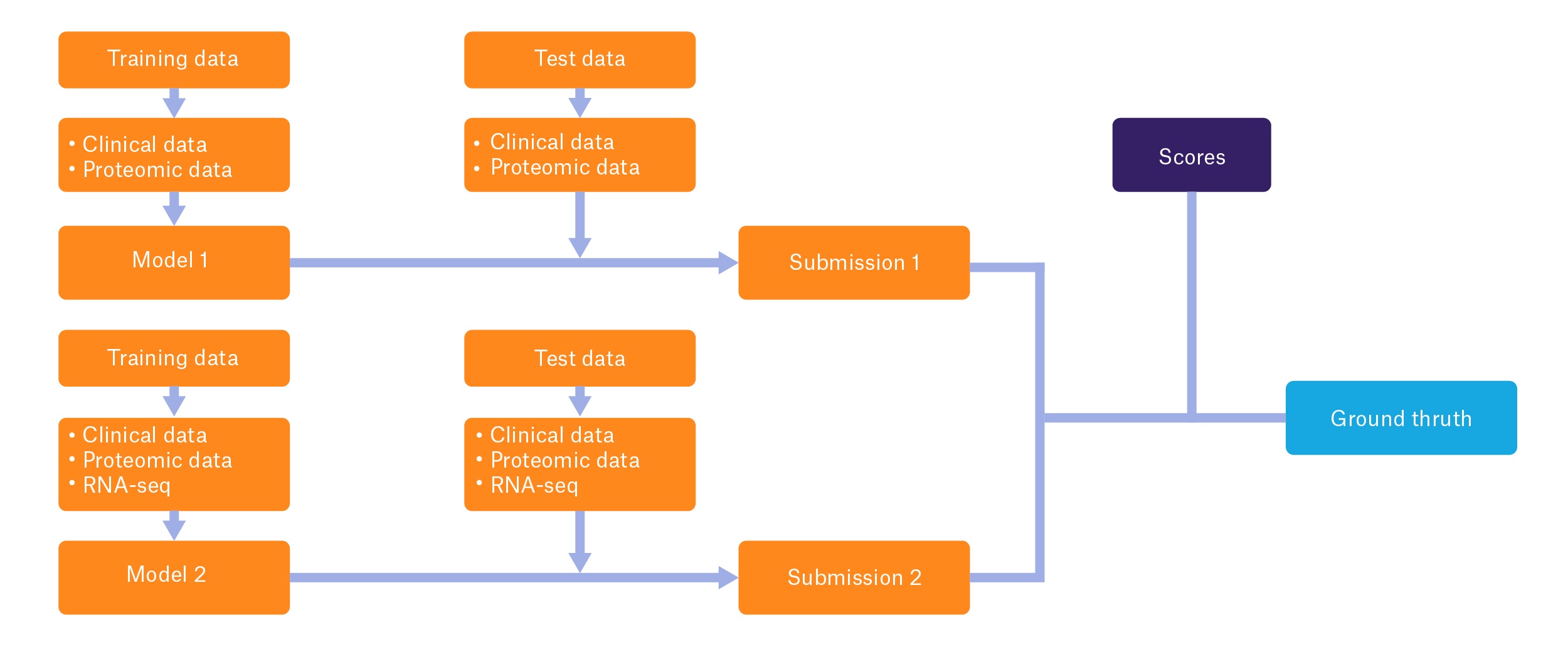
Mislabeled specimens are an especially distressing occurrence in clinical labs, particularly for patients with cancer. When tumor specimens—often required for patient diagnosis and to assess biomarkers that may guide treatment—are mislabeled, patients may not receive appropriate medical therapy. They may also be prescribed inappropriate and potentially harmful treatments.1 Furthermore, mislabeled specimens can also cost institutions hundreds of thousands of dollars as well as erode confidence in the healthcare system.2 For some patients, such as those diagnosed with advanced lung cancer, a mislabeled tumor sample may significantly impact their long-term survival and quality of life by altering treatment selection. As such, in September 2018, the US Food and Drug Administration (FDA) and the National Cancer Institute’s Clinical Proteomic Tumor Analysis Consortium sponsored a challenge to the scientific community called the “Multi-Omics Enabled Sample Mislabeling and Correction Challenge,” with the goal of promoting the development of algorithms that can detect mislabeled specimens using multi-omic datasets, including clinical data, proteomic data, and RNA-seq data.3
Multi-omics combines DNA, RNA, and protein profiles to generate a global image of individual tumors, allowing scientists to better understand the nature of the disease and to facilitate the discovery of new therapeutics. The goal of the FDA and NCI-funded initiative involves using this data to correctly identify mislabeled samples from patients with cancer. The challenge consists of two subchallenges: the first launched on September 24, with a submission date of October 21, 2018, whereas the second was launched on November 1, with an upcoming deadline of December 18, 2018. In each subchallenge, participants design a computational model using multi-omic data to discern mislabeled samples in a “training” dataset, where mislabeled samples are known, and apply their models to a “test” dataset, where mislabeled specimens are not known. Subchallenge 1 will focus on using clinical and proteomic data, while subchallenge 2 will incorporate RNA profiling data.
This initiative should serve to both promote the use of multi-omics in cancer research and to increase awareness regarding the dilemma of sample mislabeling in the clinic. However, it’s important to remember that mislabeling errors can be avoided using the proper labels for the right environment as well as technologies like barcoding and radio-frequency identification (RFID). Whether there is a need for chemical-resistant labels, cryogenic labels, or proper quality ink, it is important to make sure tubes, microscope slides, and other containers are appropriately labeled to minimize the frequency of lab errors.
LabTAG by GA International is a leading manufacturer of high-performance specialty labels and a supplier of identification solutions used in research and medical labs as well as healthcare institutions.

References:
- Kahn SE. Specimen Mislabeling: A Significant and Costly Cause of Potentially Serious Medical Errors. Brønshøj, Denmark; 2005.
- The Problem of Mislabeled Specimens. Northfield, IL; 2010.
- Boja, E; Tezak, Z.; Zhang, B.; Wang, P.; Johanson, E.; Hinton, D.; Rodriguez H. Right data for right patient—a precision FDA NCI–CPTAC Multi-omics Mislabeling Challenge. Nat Med. 2018;24:1301-1302.

{kind=link}